Tuesday Poster Session
Category: Colon


Nakul Ganju, MD
Department of Medicine, Howard University Hospital
Washington, DC
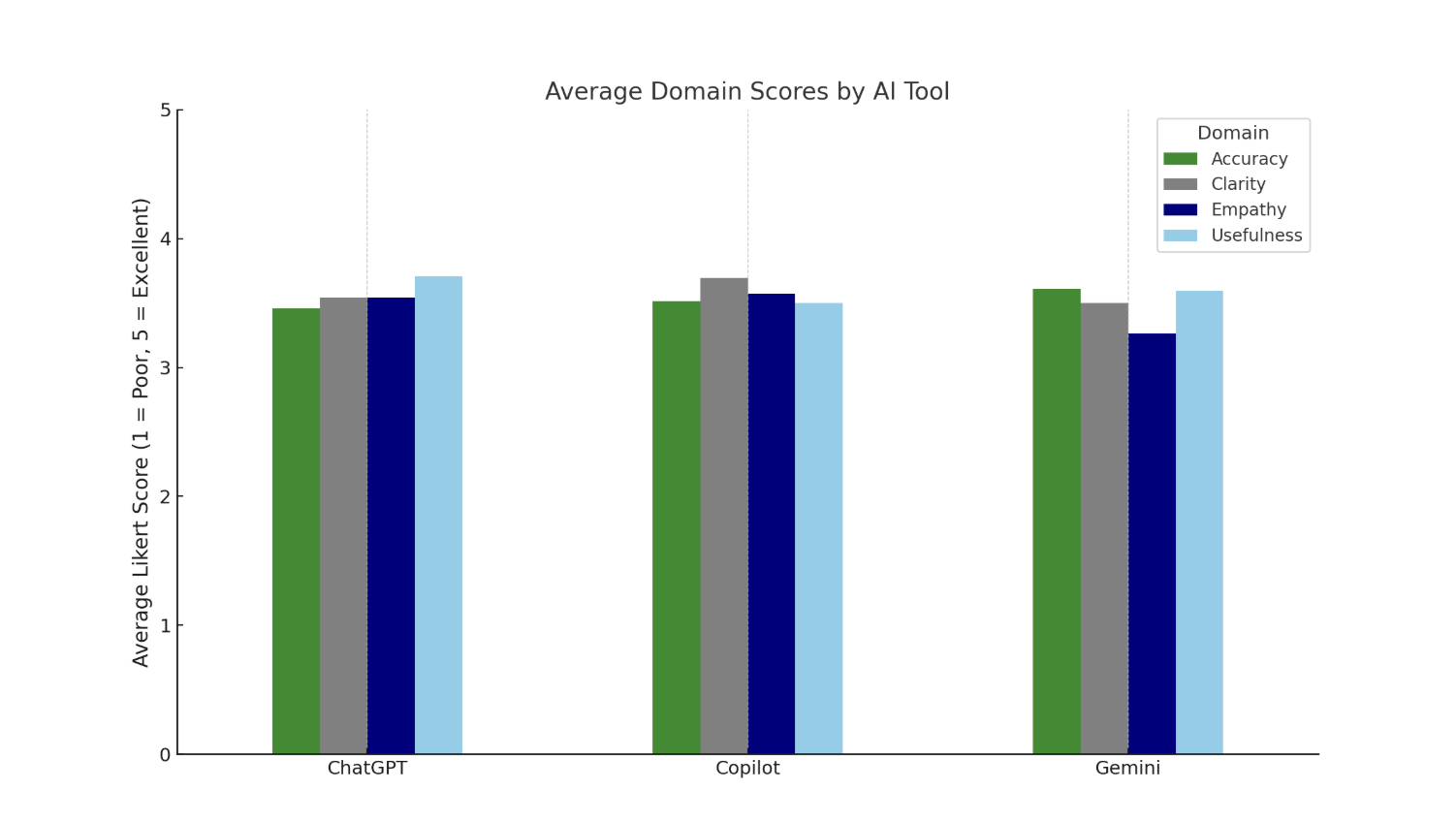
Nine evaluators (3 attendings, 6 fellows) rated chatbot responses to 8 post-colonoscopy questions across four domains. ChatGPT achieved the highest mean score for usefulness (3.71), Copilot for clarity (3.69), and Gemini for accuracy (3.61); empathy consistently rated lowest across platforms, with Gemini receiving the lowest score (3.26). Despite domain-specific variation, no statistically significant differences were found in overall performance (ANOVA p=0.677; all pairwise p >0.4). Attendings and fellows showed strong inter-rater agreement and consistent ranking patterns. These findings suggest comparable overall quality among the chatbots, with minor variation in communication attributes relevant to patient care.